Web3 is evolving. Autonomous agents, AI-driven protocols, and intelligent applications are no longer science fiction - they’re taking shape.
But there’s one thing holding them back: access to ACTIONABLE DATA.
These systems need data that is real-time, contextual, and reliable to make decisions, trigger actions, and adapt on the fly. Without it, their potential stalls.
So, what’s the bottleneck?
Why can’t today’s infrastructure keep up?
And how does Hyperbola aim to unlock this next leap?
Let’s unpack the core challenge - and the bold vision shaping a new kind of data layer for the agentic Web3 ecosystem.
The Evolution of Data Needs in Applications
What Is Data, and Why It Matters
Data is the most essential component of any application, its just like how oxygen sustains life, data gives applications the ability to act, react, and evolve. Without data, even the most beautifully coded application is just static art — pretty, but purposeless.
Data Schema
Data schema is a way representation of predefined structure a program or a logic can understand to take any actions it can be as simple as
{ status: “success”, Message: “ Validation was successful” }
Data schema as evolved over years from xml, json to Static to Dynamic Data shift
Modern day applications need Dynamic with Dynamic schema,
A data schema defines the structure in which data is organized - a blueprint that applications use to understand and act on it.
Example:
{ "status": "success", "message": "Validation was successful" }
Over the decades, data schemas have evolved:
- From rigid structures like XML
- To lightweight JSON
- To flexible, dynamic formats powering today’s intelligent systems
DATA NEEDS over the period of time have evolved evolution from static to dynamic to actionable data.
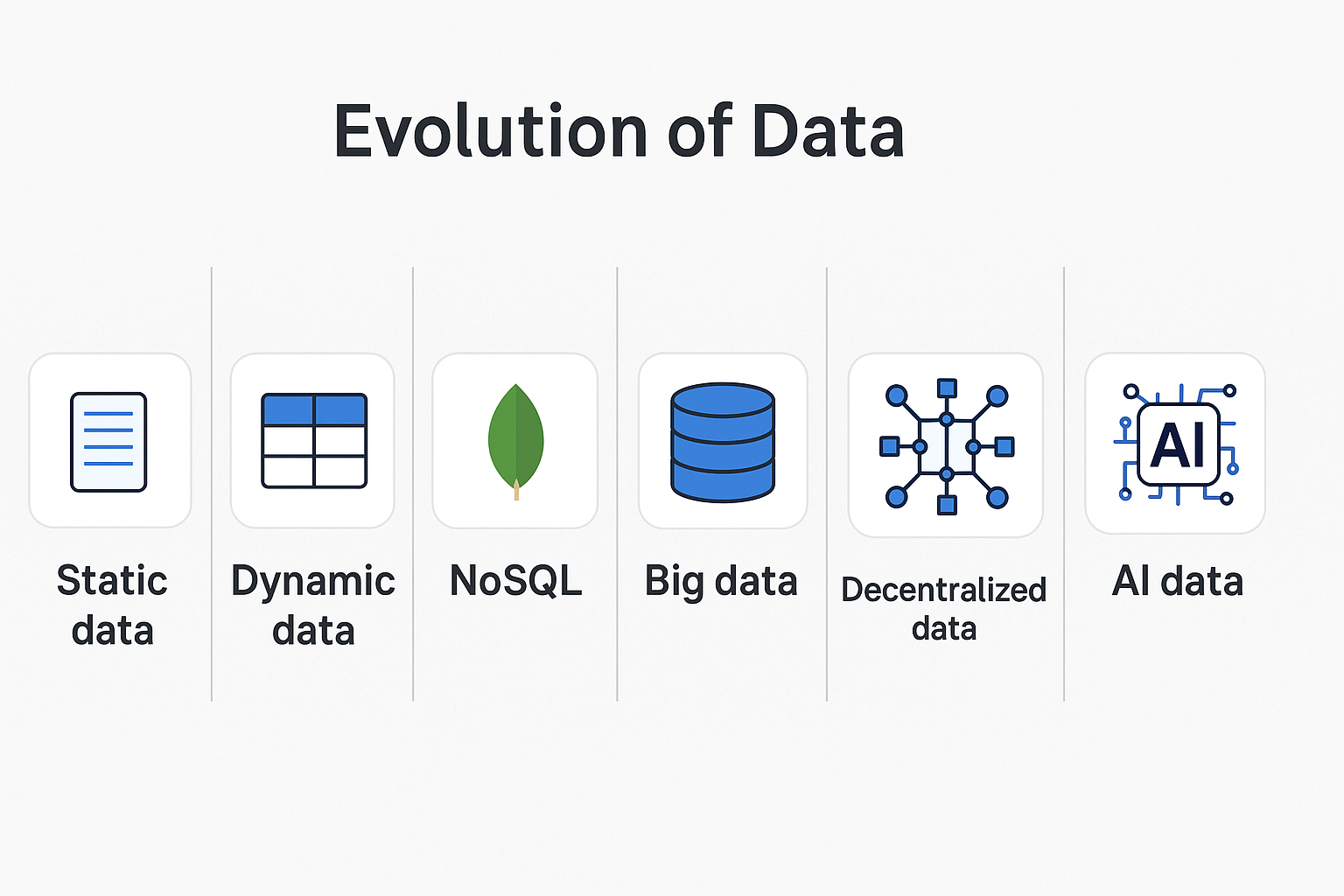
- Static Data – CSV, XML
- Dynamic (Relational) Data – MySQL, PostgreSQL
- Scalable (NoSQL) Data – MongoDB, Firebase
- Real-Time / Streaming Data – Kafka, Flink
- Big Data – Hadoop, Spark
- Decentralized Data – IPFS, Arweave
- Agentic / AI-Native Data – Vector DBs, DAGs, RAG pipelines
Data: Fuel for AI, Agents and Autonomous EcoSystems
In the world of AI and autonomous systems, data isn’t just input - it’s the core operating layer. It powers everything from perception to decision-making to execution.
Autonomous agents, whether they’re AI co-pilots, trading bots, governance actors, or task execution frameworks, make decisions by observing the environment, processing data in real time, and acting accordingly. But for them to work effectively, the data must be actionable - structured, current, and directly tied to the agent’s goal.
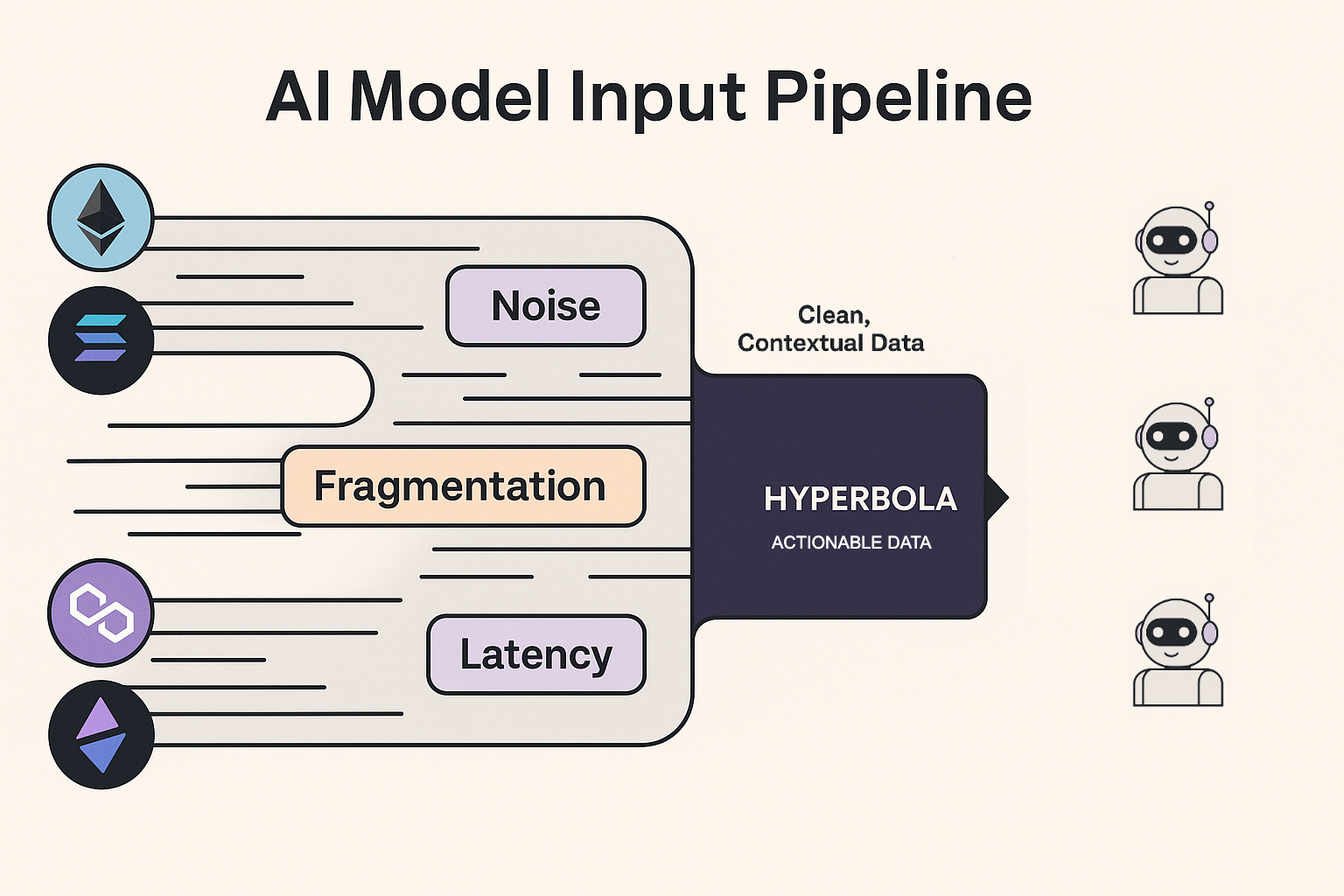
In an autonomous ecosystem, latency and fragmentation are deadly. If an agent receives stale, incomplete, or misaligned data, it doesn’t just slow down - it fails.
This is a critical challenge in Web3, where data is inherently fragmented across chains, formats, and access layers. The lack of unified, actionable data is one of the biggest blockers holding back the next generation of autonomous Web3 applications.
Web3 Data and Challenges
How Ethereum was able to survive all this years against mighty Bitcoin
Bitcoin’s blockchain was built to be a book keeper - a decentralized store for recording transactional information. Its purpose was singular, and its design reflected that minimalism.
Ethereum, on the other hand, imagined something more ambitious.
It didn’t just record value, ethereum was enabled developers to program it. By enabling the storage of data and the execution of smart contracts. Suddenly, the blockchain wasn’t just a place to record transactions - it became a place build apps using data stored and execution capabalities.
This shift unlocked entirely new categories of applications:
- Lending markets
- Governance systems
- NFT economies
- Decentralized exchanges
All of DeFi - and much of Web3 - stands on this foundation.
in DeFi However with new gen applications which is data hungry, needing reliable and low latency data is a big hurdle which is stifling innovation to nurture
Current day challenges and complexities
Web3 data is powerful by design - decentralized, verifiable, and tamper-proof. But that same design introduces deep complexity. Each blockchain speaks its own language: different schemas, data structures, access methods, and update cycles. There’s no universal interface - only fragmented endpoints, custom RPCs, and brittle APIs.
For developers and businesses alike, this creates friction. Accessing data across chains means wrestling with inconsistent formats, building custom indexers, and maintaining fragile infrastructure.
Real-time use cases - like trading bots, credit systems, or automated workflows - need speed and precision, but today’s data stack simply can’t deliver both. The result? Slower innovation, higher costs, and missed opportunities in a space meant to move fast.
Fragmentation challenges in Web3 data
-
Every Chain Speaks a Different Language
Each blockchain has its own data structures, schemas, and access methods - there’s no standard way to query or interact across ecosystems.
-
No Unified Access or Interface
Developers must juggle RPCs, custom APIs, and indexers for each chain, often building custom infrastructure just to read basic data.
-
Real-Time is Still a Dream
Data is often delayed, inconsistent, or incomplete - making real-time, multi-chain applications fragile and hard to scale.
Scattered Solutions
With modern Day problems modern day solutions evolve, Due to this challenges in web3 data a lot of solutions evolved like Data Abstractions, Data Accessibility
Data Layer:
This is foundational layer where data is stored, with primary function to store and manage data ( CRUD ) Many are trying to address the problems, but they are aimed at ensuring the data is made accessible to applications, however there is one big problem with this, with this again one needs to know how to program around the shared outcome
Data Availability Layer:
Sole purpose is to ensure there is data Its meant to ensure transaction data is available to anyone to verify blockchain data Storing transaction data Making data accessible to full nodes Ensuring data can be retrieved efficiently
Celstia : Modular Blockchain designed for data availability
Avail : modular DA layer focused on scalability and decentralization Players like Rollups, Validators, light chains use them
Data Accessibility Layer:
Its sole purpose is to ensure data is easy to use On the other hand Data accessibility layers are infrastructures to make blockchain data more usable Basically it’s a bridge between blockchain data and Usable infrastructure for web3 apps. Its more on usability side of the game Indexing Blockchain data Provide Structured data interfaces like API Enabling realtime or historical data for dapps Application layers like Wallets, dapps, Dashboards use them All these layers work closely
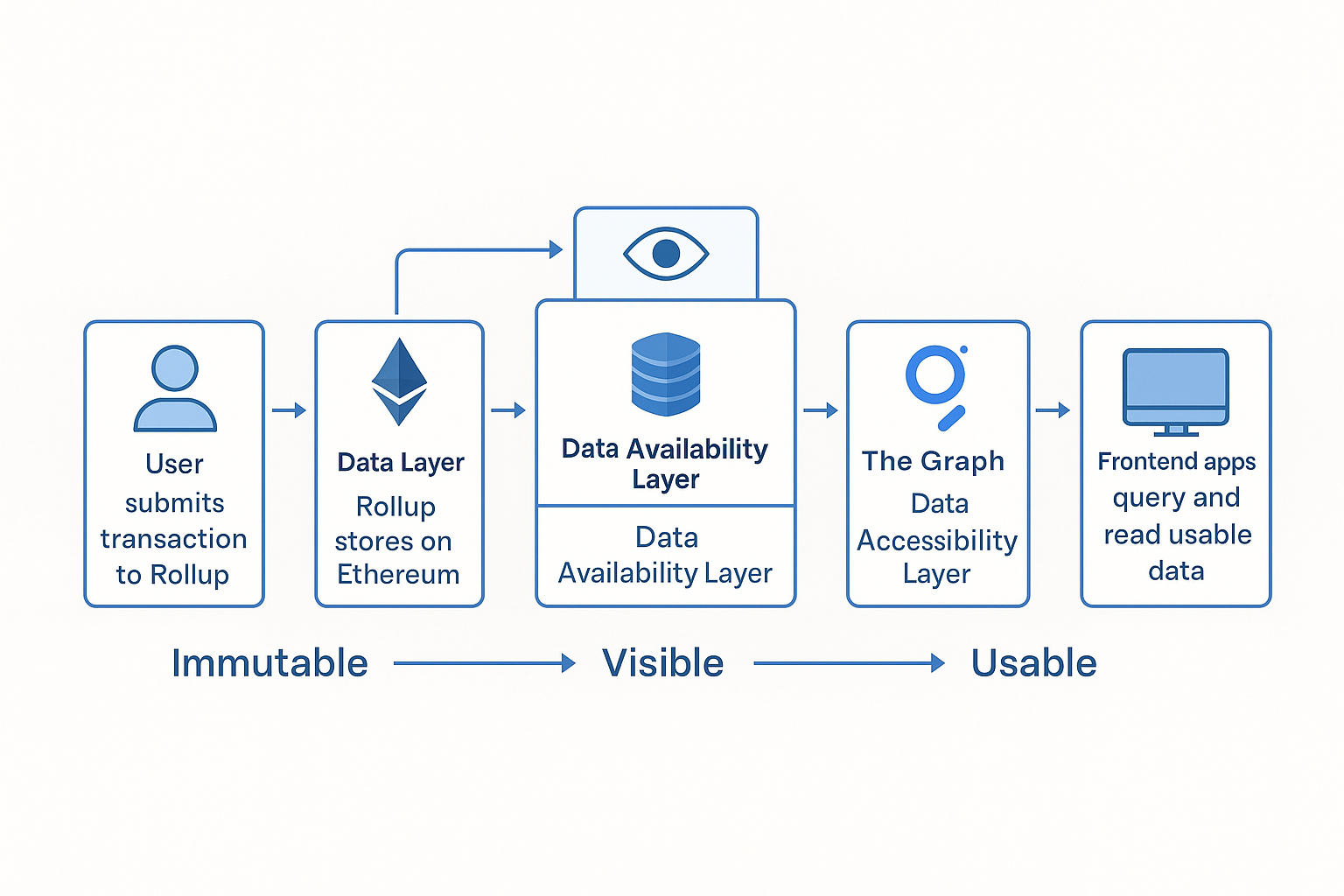
Imagine a rollup on Ethereum:
- Data Layer ( Ensures data is stored ) : Ethereum stores the rollup's transaction commitments.
- Data Availability Layer ( Ensure Visibility) : Ethereum (or Celestia) ensures the full transaction data is published, not just a hash.
- Data Accessibility Layer ( Ensures data is usable ) : A tool like The Graph lets you query user balances or contract events without parsing raw Ethereum blocks.
What’s next, Current infrastructure is good and evolving to support existing dapps their needs, but It also comes with set of limitations Dapps need to stick to predefined set of Data Schema, still need to Stitch multiple layers and apis
With growing adoption in With AI, Agents, tools and autonomous applications they purely rely on actionable data, with modern day solutions its broken Lets understand growing need of Actionable data
Role of Actionable Data in NextGen Autonomous Web3 Applications
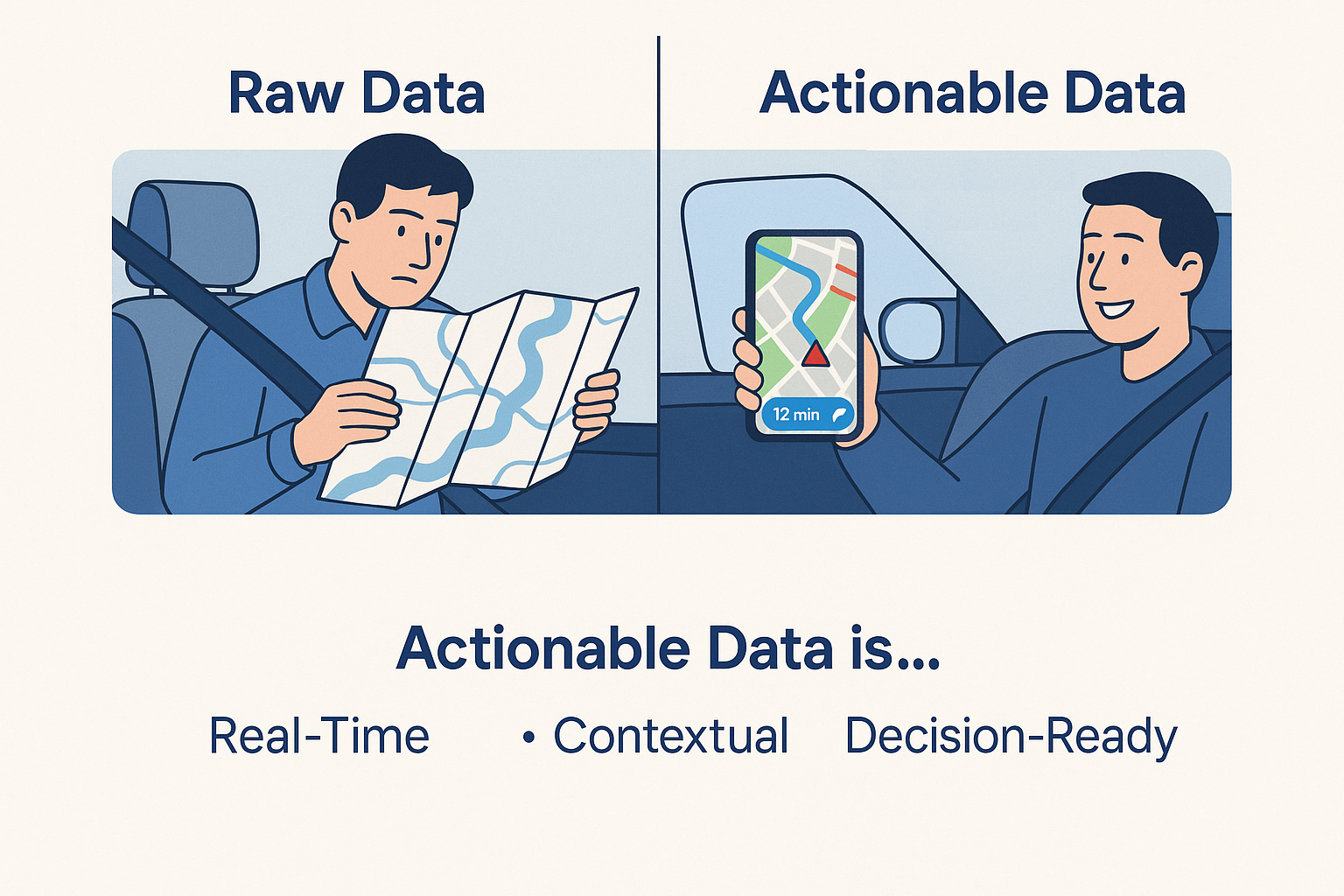
Actionable Data
An actionable data is data that is processed, relevant and structured in a way that allows individuals to take informed actions or decisions immediately
Actionable data is contextual, dynamic/real time , reliable for a specific purpose or a goal.
Autonomous agents
They are the AI agents that define automation, that can take decisions and act on its own,
without needing anyone to tell what to do. They need aggressive real time, relevant and contextual data to be able to function accurately,
Autonomous agents success depends on actionable data, They are the future of AI automation, to automate workflows, strategies, Analytics,
Where apps are headed with AI, Autonomous Agents
With growing popularity on AI based applications autonomous agents need for actionable data is immense, without actionable data agents fail to deliver results, additionally latency and complexity in accessing data is still a challenge.
AI agents need data to make informed decisions, current infrastructure way too fragmented to support them With web3 Autonomous Agents in rise they are bound by limitations on fragmented Blockchain data, even current MCP servers are new in the space and broken.
Intro to Hyperbola
We’ve seen that next-gen autonomous applications, from AI agents to automated protocols - depend on actionable data to function effectively. They require data that is reliable, low-latency, and context-aware to make real-time decisions and take meaningful actions.
However, the current Web3 infrastructure struggles to meet these demands. Fragmented layers, inconsistent access patterns, and stale data pipelines leave autonomous agents underpowered and prone to failure.
This is where Hyperbola enters - not just as another data tool, but as a reimagined data infrastructure layer for Web3. Built specifically for the era of AI, agents, and autonomous applications, Hyperbola focuses on the one thing these systems cannot function without: actionable data.
Unlike other platforms that solve for just one layer - storage, availability, or access. Hyperbola acts as an intent-driven data layer for agents that sits across the entire data stack. It connects the Data Layer (where raw blockchain data resides), the Data Availability Layer (which ensures full, retrievable access), and the Data Accessibility Layer (which structures the data for consumption). But it doesn’t stop there. Hyperbola fuses these layers into a cohesive system that outputs real-time, contextual, custom-schema data ready to be consumed by autonomous agents, dApps, or analytics systems.
At the core of Hyperbola has an intelligent system that understands intent . Whether it’s an autonomous agent trying to rebalance a portfolio, a DAO dashboard querying governance activity, or a trading protocol scanning for liquidity shifts, Hyperbola translates those intents into structured data workflows. These workflows are executed via a Synaptic engine(SE) that pulls from multiple data providers, filters for relevance, ensures realtime, validates accuracy, and returns the data in a goal-specific, specific schema, actionable format. In short: it thinks like the application it’s serving.
To make this possible, Hyperbola is built on four core components:
- AI Engine – Parses natural language or declarative intents into executable queries
- Synaptic Engine – Orchestrates data retrieval from multiple sources
- Knowledge Pool – A knowledge layer that has information on all available informations in the form of data, previously executed paths,
- Data Providers – Integrated across L1s, L2s, subgraphs, RPC endpoints, DA layers, and oracles
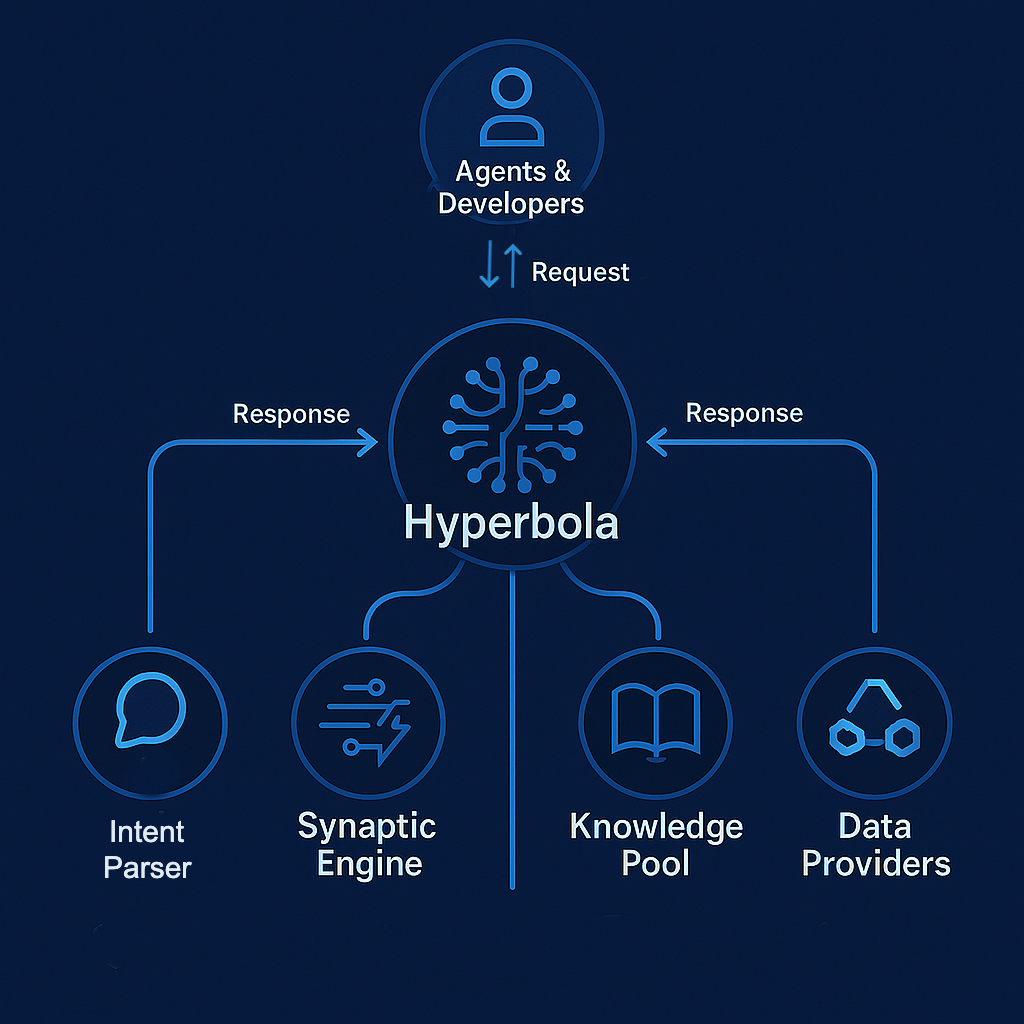
This modular design allows Hyperbola to abstract away complexity while remaining extensible across chains, use cases, and future data standards. Developers don’t have to build custom indexers. Agents don’t need to know which RPCs to call. Every application can simply plug into Hyperbola and start receiving structured, intelligent data - in the right format, with the right context, at the right time.
As Web3 moves toward a future of Agentic, AI-driven automation, the infrastructure must evolve beyond static APIs and fragmented endpoints. Hyperbola represents this evolution. It’s not just a data pipeline - it’s a data nervous system for decentralized intelligence. By making data truly actionable, Hyperbola empowers applications not just to read the blockchain, but to understand it, respond to it, and build on top of it in real time.
Use Cases where Hyperbola can excel
- Businesses building chain agnostic solutions
- Autonomous Agents ( DeFi automations, Governance, Trading Bots, Research Agents,)
Hyperbolas Vision : A self-learning, plug-and-play engine that:
- Accepts natural language intents
- Consults a registry of schema, filters, and APIs
- Generates executable data DAGs
- Runs across databases and services in parallel/series
- Improves over time through a learning knowledge base
Achievement
IGRIS: MultiChain Executor
One powerful example of this vision in action is Igris.bot, a proof-of-concept agent built on top of Hyperbola. Igris is an autonomous swap assistant that executes destination, and price-based token swaps across multiple EVM chains. What makes Igris intelligent isn’t just smart routing logic - it’s the actionable data it receives from Hyperbola.
Using Hyperbola’s APIs, Igris can identify token metadata, access real-time price feeds, and dynamically retrieve optimal route data. It acts as an on-chain pathfinder - selecting the cheapest and fastest route in response to user intent. From parsing a natural language input to triggering a cross-chain execution, Igris showcases how Hyperbola enables agents to go from intent to action with no manual intervention.

Unlocking the Next Generation of Web3 Intelligence
The implications of actionable data is massive. Hyperbola aims to foster a environment where developers can build dashboards that think like analysts, agents that behave like operators, and smart contracts that react to the world in real time. Whether it's powering cross-chain credit systems, autonomous DeFi strategies, decentralized search, or multi-chain governance orchestration - Hyperbola aims to enable a new class of intelligent, responsive, and scalable Web3 applications.
If you’re building the future of AI x Web3, the question is no longer how to get data - it’s how to make it actionable.
Hyperbola is the missing layer that brings intent, infrastructure, and intelligence together.